Model distillation
Training a small model to mimic a large one by learning from its output distributions rather than raw labels.
Learn first
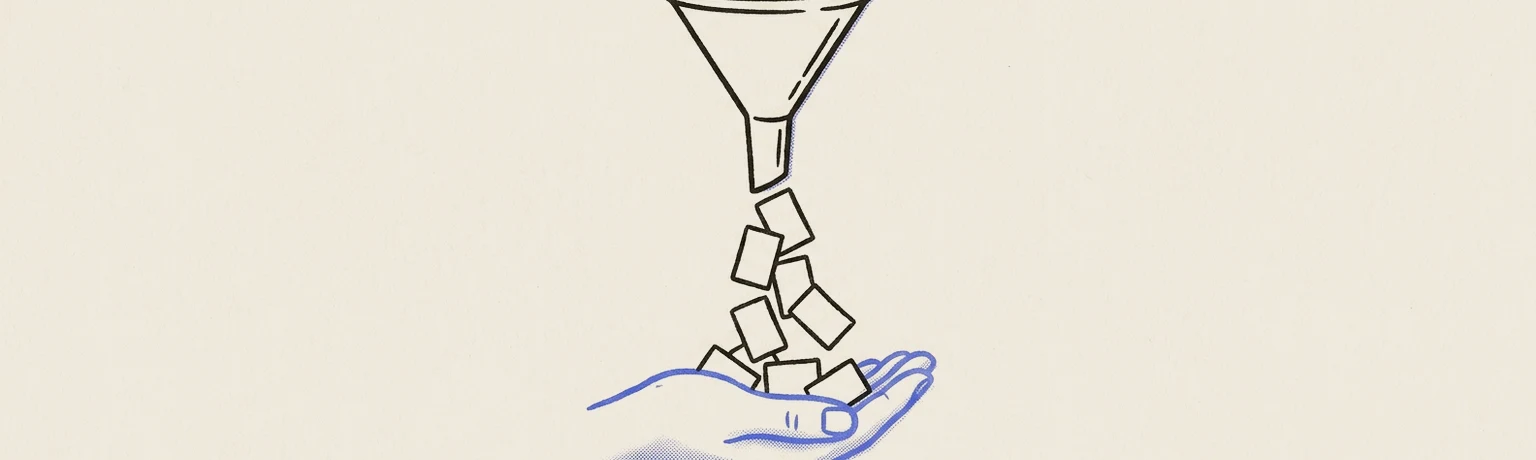
A large model (the teacher) generates soft probability distributions over answers — not just the correct label but how confident it is across all possibilities. A smaller model (the student) trains on those distributions instead of hard labels, absorbing the teacher's generalizations. The student ends up far more capable than its size would predict from scratch. The hard part: the student must be large enough to hold what the teacher knows, and the teacher's outputs must be better-calibrated than noisy human labels — otherwise you distill the errors too.
Where it came from
In megatrends
Finds citing this concept
Overall = breadth + depth + substance + ½·novelty + freshness (a small boost that halves each week)
The 29-million-answer letter
Anthropic told US senators that operators it ties to Alibaba's Qwen lab opened roughly 25,000 fake accounts and pulled nearly 29 million answers out of Claude in six weeks — and asked Congress for sanctions in the same breath.
How this connects
Tap a node to open it