Ask, don't rate
When an AI is asked to grade another AI's work from 1 to 5, it piles almost everything into 3 and 4 — so a new paper throws out the scale and asks a stack of yes/no questions instead.
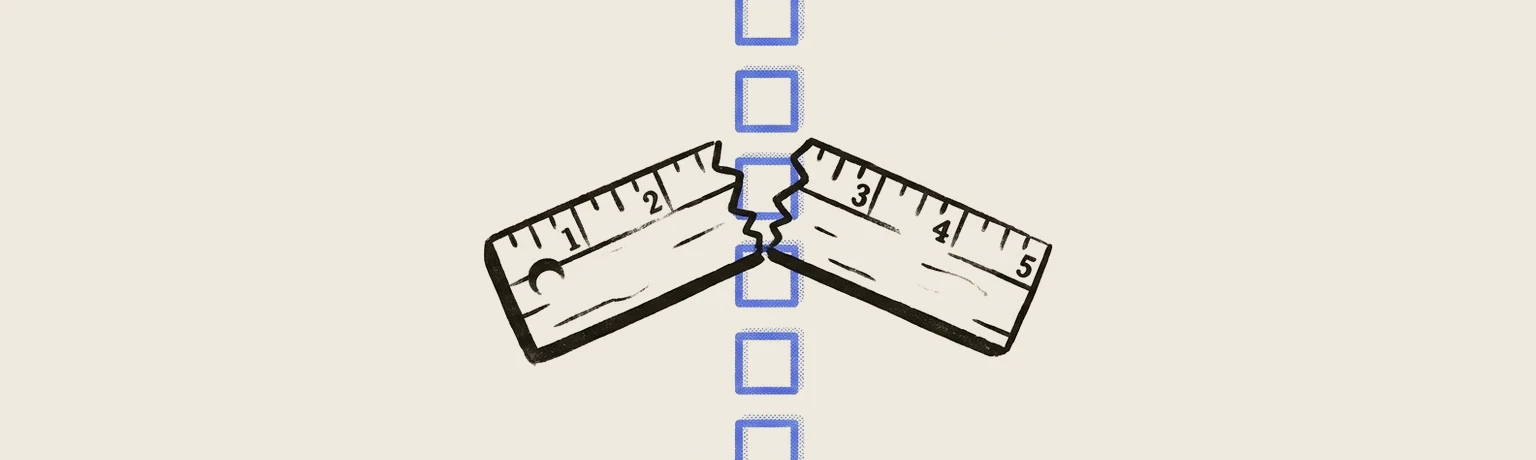
Hand an AI the job of grading another model's output on a 1-to-5 scale and a strange thing happens: the scores bunch up in the middle, mostly 3s and 4s, and they slide around between runs when you so much as reword the instructions. A number that won't hold still is useless for catching regressions. The fix that practitioners have converged on, and that a new arXiv paper called BINEVAL now formalizes and benchmarks, is almost insultingly plain — stop asking for a rating and ask a pile of yes-or-no questions. Did the summary contradict the source? Did it drop the main point? Each verdict is a clean bit, and the bits add up into a score that tracks human judgment more closely than the holistic number did.
A model asked for a 4 is emitting an uncalibrated token that means little run to run; forced to say yes or no, it has nowhere to hide.
The reason binary works is the same reason the rating fails. A model forced to commit to 'yes' or 'no' has nowhere to hide; a model asked for a 4 is emitting an uncalibrated token that means little run to run — and bigger reasoning models don't rescue it, because the output is still a discrete guess, not a measurement. Decomposing the question is what makes the answer legible: instead of an opaque grade you get a checklist you can read.
What's notable is the order of events. The engineers who run these evaluation pipelines have been teaching binary-over-numeric for more than a year; an independent controlled test last autumn found numeric scores 'bunch, flip, or collapse' while categorical labels stayed put. The paper is the academy catching up to the shop floor — which is its own small lesson about where method actually comes from in this field.
The lenses
The facts
Concepts
How this connects
Tap a node to open it